Java内存模型,简称JMM(java memory model),随着计算机性能的不断提升,计算机的运算速度与它的存储能力和通信子系统的速度差距越拉越大,计算机的运算速度高出存储和通信速度好多个量级,为了减少这种速度差异,因此但是了3级缓存.高速缓存虽然很好的解决了CPU和内存的速度矛盾,但是又引入了新的问题—缓存一致性问题. JMM 就是为了解决这类

神秘组织定义的组织规定???
操作系统底层
首先我们回忆下计算机组成原理中 CPU ,内存,硬盘是怎么通讯的.
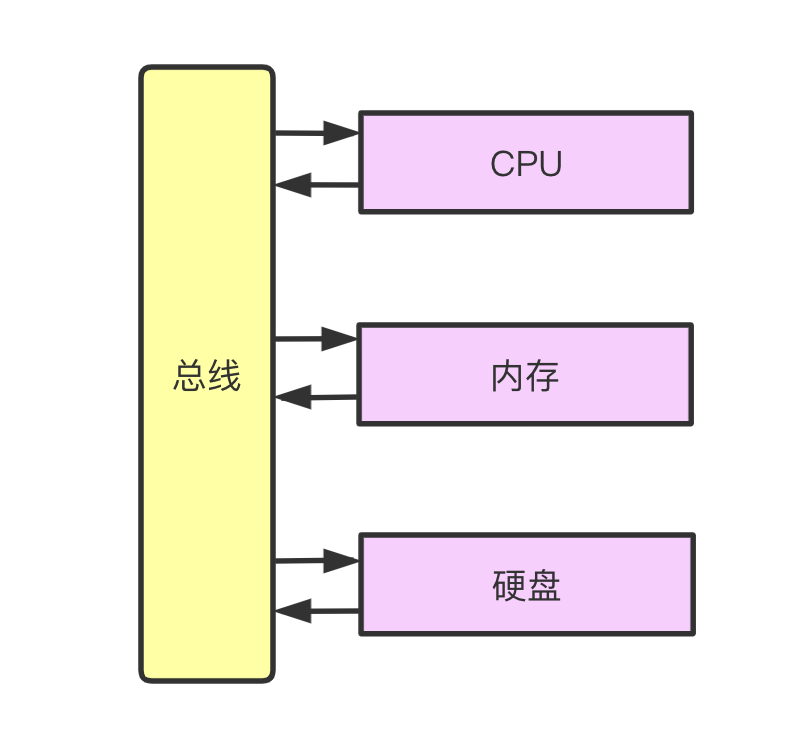
数据是通过数据总线在CPU,内存,硬盘中传输的,总线包括数据总线,控制总线,地址总线.
一般数据CPU不会直接访问硬盘而是通过访问内存获取数据:
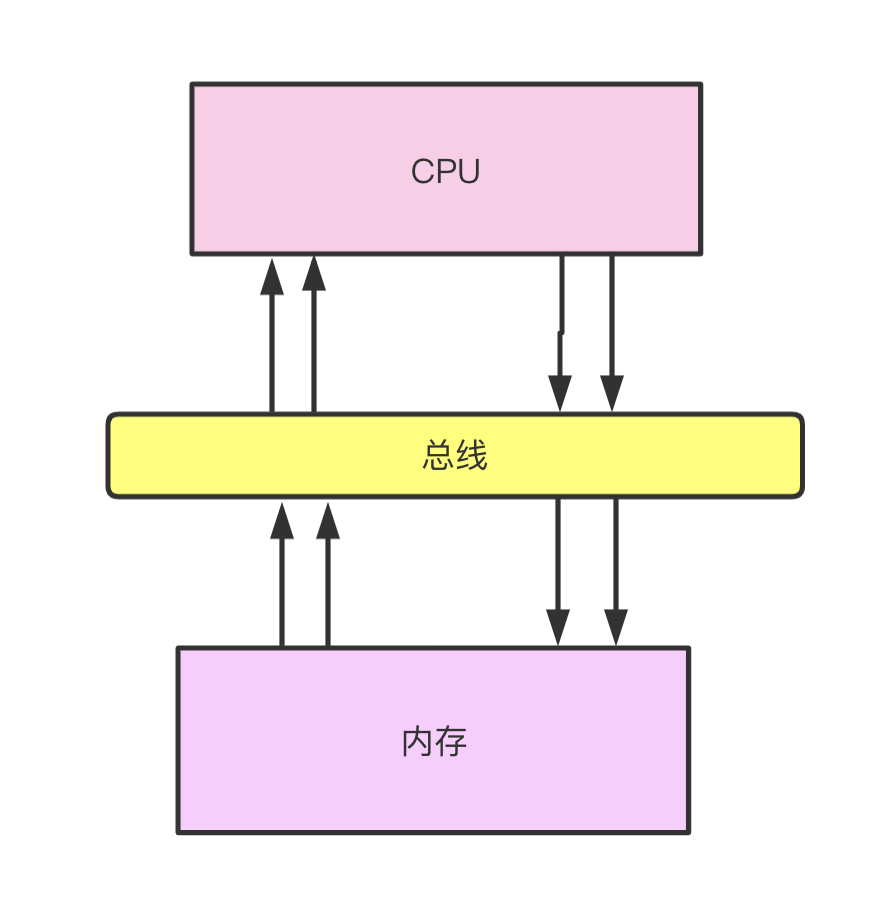
如开篇之前所说,随着CPU运算能力的提升,计算机的I/O能力以及通信系统的速度远跟不上CPU的算力.因此引入了多级缓存结构,来进一步提升执行效率,减少CPU与内存的交互.
常用的有3级缓存结构. 如下图所示:
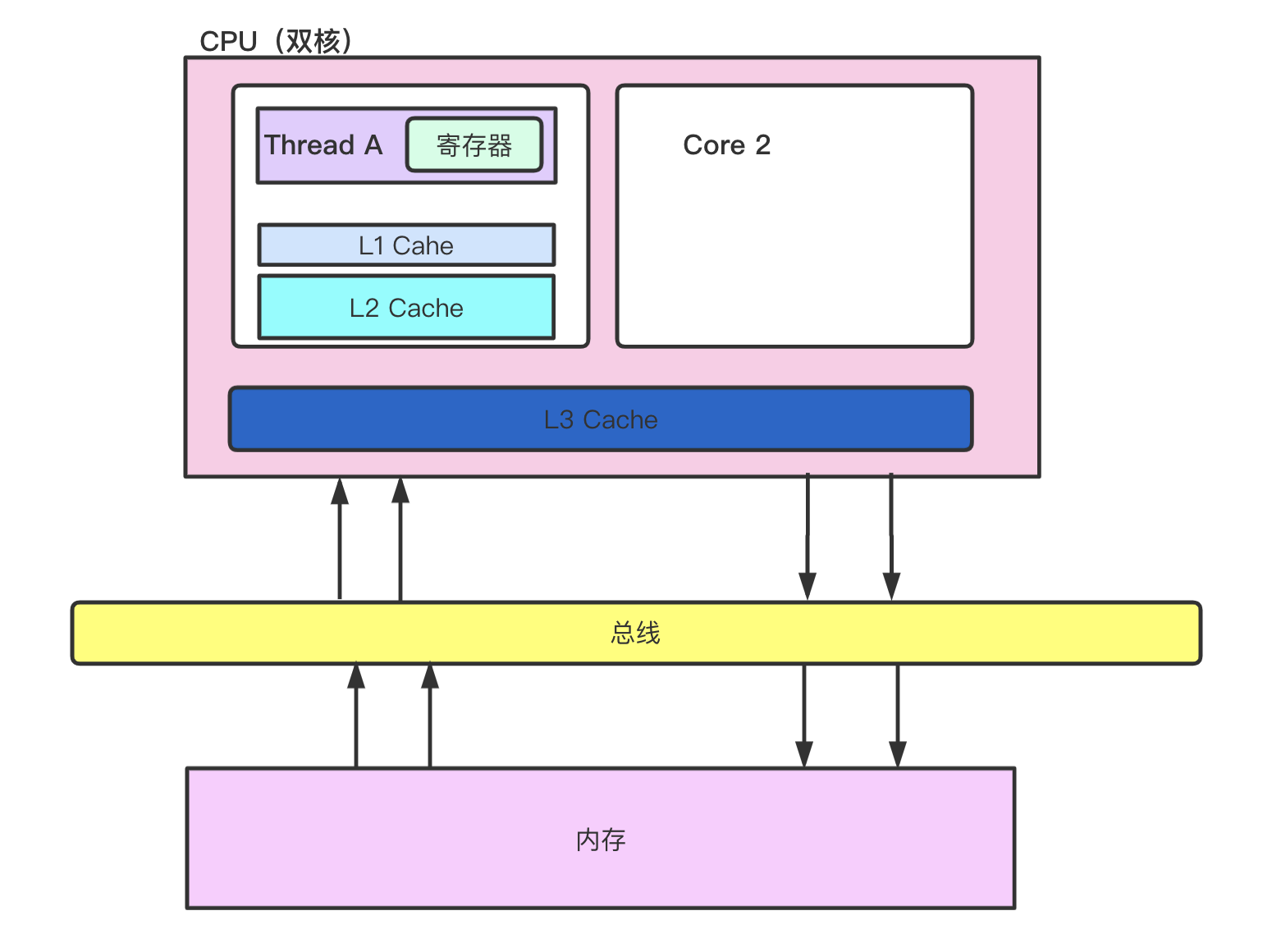
L1 Cache : 分为数据缓存和指令缓存, 逻辑核独占
L2 Cache,物理核独占,逻辑核共享
L3 Cache,所有物理核共享
存储器大小: 内存 > L3 > L2 > L1 > 寄存器
存储器速度: 内存 < L3 < L2 < L1 < 寄存器
需要注意的是:
缓存是由最小的缓存行(CacheLine)组成的 ,缓存大小通常是64byte.
这里以Mac为例:
执行命令
1 | sysctl -a |
CPU厂商在CPU中内置了一些高速缓存以解决I/O速度和CPU运算速度之间的不匹配问题.
在CPU访问存储设备时,无论是存取数据或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理.
局部性原理分为:
- 时间局部性: 如果一个数据正在被使用,那它在近期很有可能会被再次访问
- 空间局部性: 如果一个存储器的位置被引用,那它附件的位置也很有可能会被引用.
共享能避免吗?
在 JDK 8之前,一般都是通过字节填充的方式来避免该问题.
JDK 8提供了一个 sun.misc.Contended注解.
1 | .misc.Contended("tlr") |
@Contended 注解只用于 Java 核心 类,比如此包下的类.如果用户类路径下的类需要使用这个注解, 则 需要添加 NM 参数 :-XX:-RestrictContended.
填充的宽度默认为 128,要自定义宽度则可以设置 -XX:Con nd巳dPaddingWidth 参数.
如何证明局部性原理的在计算机中真正的存在呢?
时间局部性证明:
有点类似LruCache算法,当Cache存储空间不够的情况下会将最近最少使用的空间释放出来.
空间局部性证明:
假设有一个很大的数组 array[1000][10], 里面充满了数值,通过如下两种方式求和所有的元素之和. 猜猜看,速度会有明显差异吗? 如果有差异,那是为什么呢?
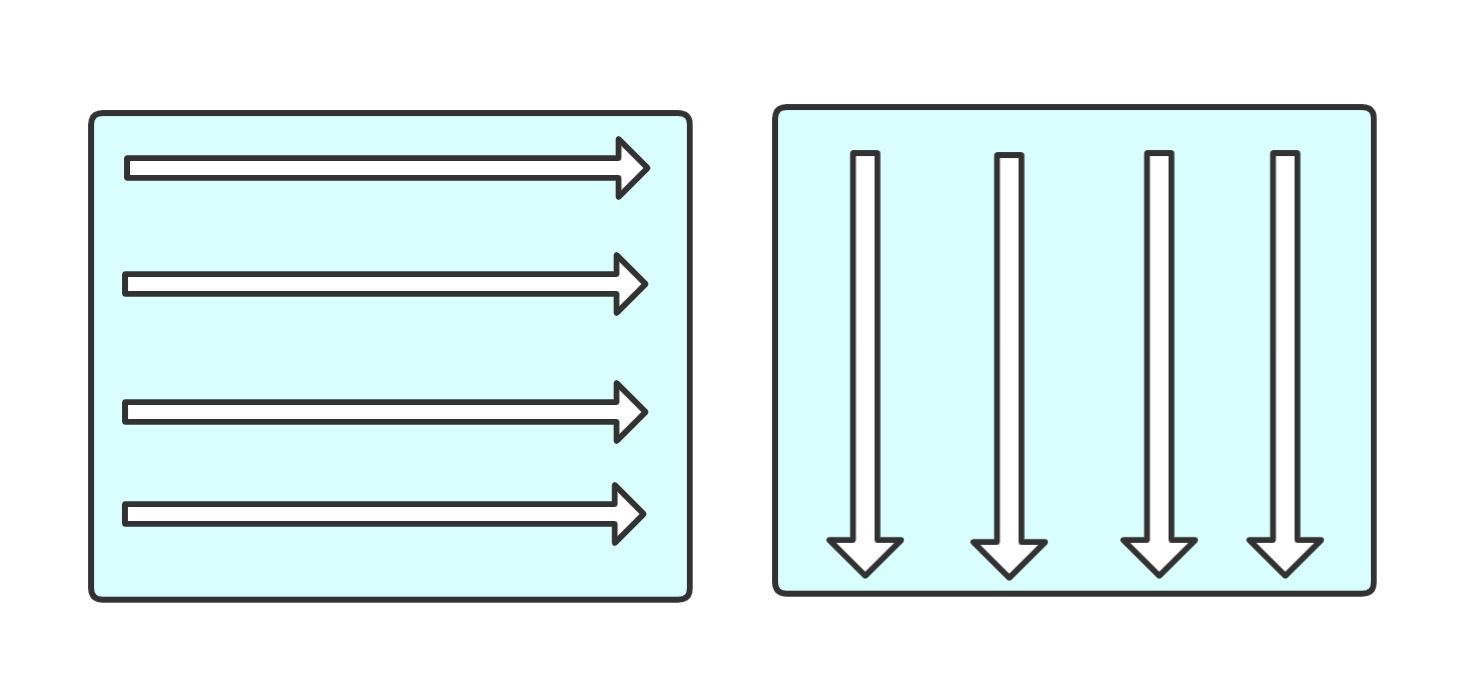
事实证明: 左边的遍历方式速度 会明显快于 右边的遍历方式.
让你结合空间局部性 你能想明白为什么吗?
存储数组的空间是连续的,按照左边遍历的方式,假如读取第一元素的时候,根据空间局部性,将连续的数据加载进缓存行,也就是说第二个元素也一并被加载进了Cache,减少了CPU和内存直接的通信.
而右边的遍历方式,虽然也根据空间局部性加载了附件存储位置的数据,但是我们的逻辑中并未用到,每次都需要重新加载.
KLT & ULT
操作系统有用户空间与内核空间两个概念,目的也是为了做到程序运行安全隔离与稳定,以 32位操作系统4G大小的内存空间为例:
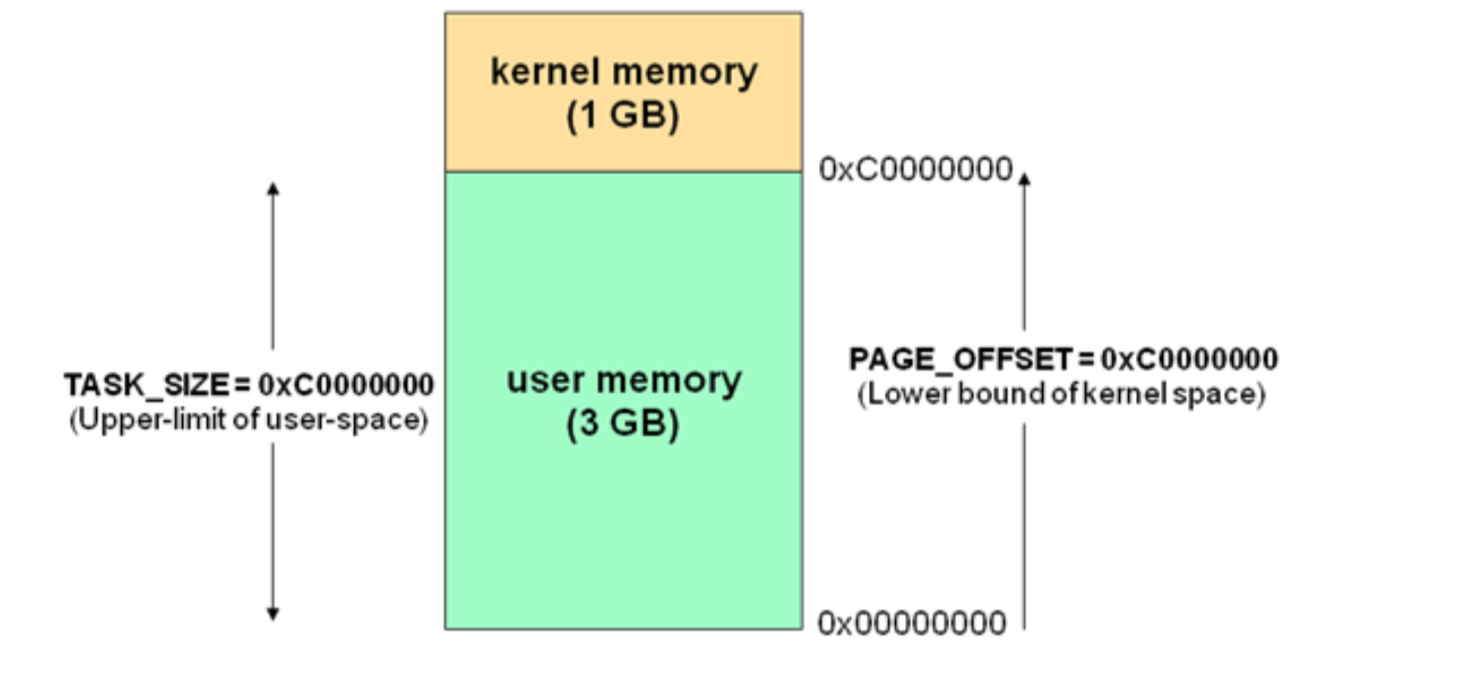
- 0x00000000 到 0xc0000000(PAGE_OFFSET) 的线性地址可由用户代码 和 内核代码进 行引用(即用户空间)
- 从0xc0000000(PAGE_OFFSET)到 0xFFFFFFFFF的线性地址只 能由内核代码进行访问(即内核空间)
在 4 GB 的内存空间中,只有 3 GB 可以用于用户应用程序.进程与线程只能 运行在用户方式(usermode)或内核方式(kernelmode)下.用户程序运行在用户方式下,而系统调用运行在内核方式下.
根据空间划分:
- 内核线程模型(KLT)
- 用户线程模型(ULT)
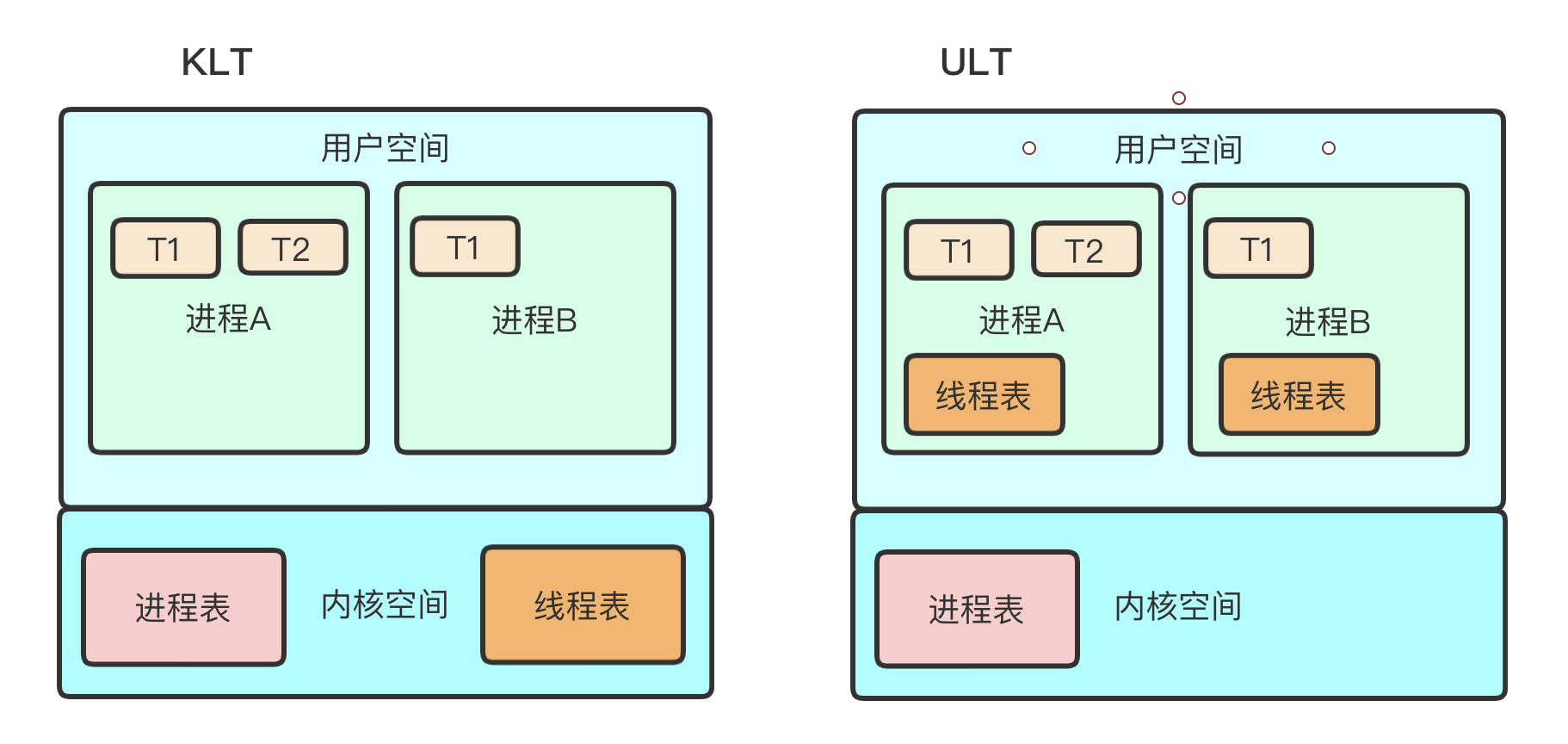
- 内核线程(KLT):系统内核管理线程(KLT),内核保存线程的状态和上下文信息,线程阻塞不会引起进程阻塞.在多处理器系统上,多线程在多处理器上并行运行.线程的创建、调度和管 理由内核完成,效率比ULT要慢,比进程操作快.
- 用户线程(ULT):用户程序实现,不依赖操作系统核心,应用提供创建,同步,调度和管理线程
的函数来控制用户线程。不需要用户态/内核态切换,速度快.内核对ULT无感知,线程阻塞则进程(包括它的所有线程)阻塞.
我们的JVM 采用的就是KLT模型.
JMM
Java 虚拟机规范中试图定义一种Java 内存模型来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果.—摘自<深入理解Java虚拟机>
下面我们先来看下 线程,工作内存,主内存 之间的交互关系:
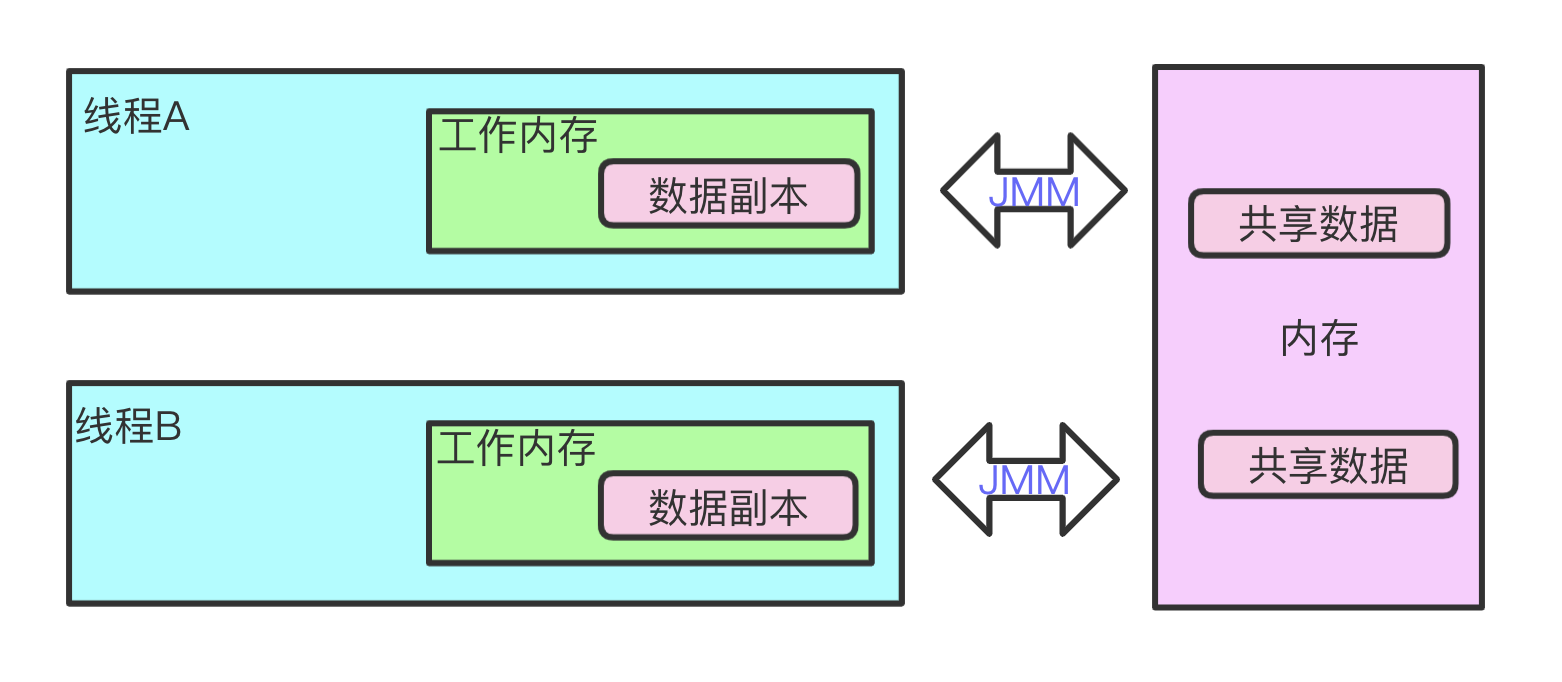
主内存: 主要存储共享数据.
工作内存: 每个线程都有自己的独立工作内存,对于其他线程是不可见的,这里我们忘记3层缓存模型,直接把线程内部的寄存器区理解为工作内存. 最终线程执行操作将从工作内存获取数据.
内存建交互操作
java 内存模型定义了8种原子操作,不可拆分的操作来完成数据在内存中的交互. 它们分别是:
- lock (锁定): 作用于主内存的变量,把一个变量标记为一条线程独占状态
- unlock (解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read (读取):作用于主内存的变量,从主内存读取数据
- load (载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中
- use (使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎
- assign (赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量
- store (存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作
- write (写入):作用于工作内存的变量,它把store操作从工作内存中的一个变量的值传送到主内存的变量中
一个共享数据从主内存中加载到内存, 值得注意的是,线程加载到的数据是主内存共享数据的一个副部.
完整的流程图:
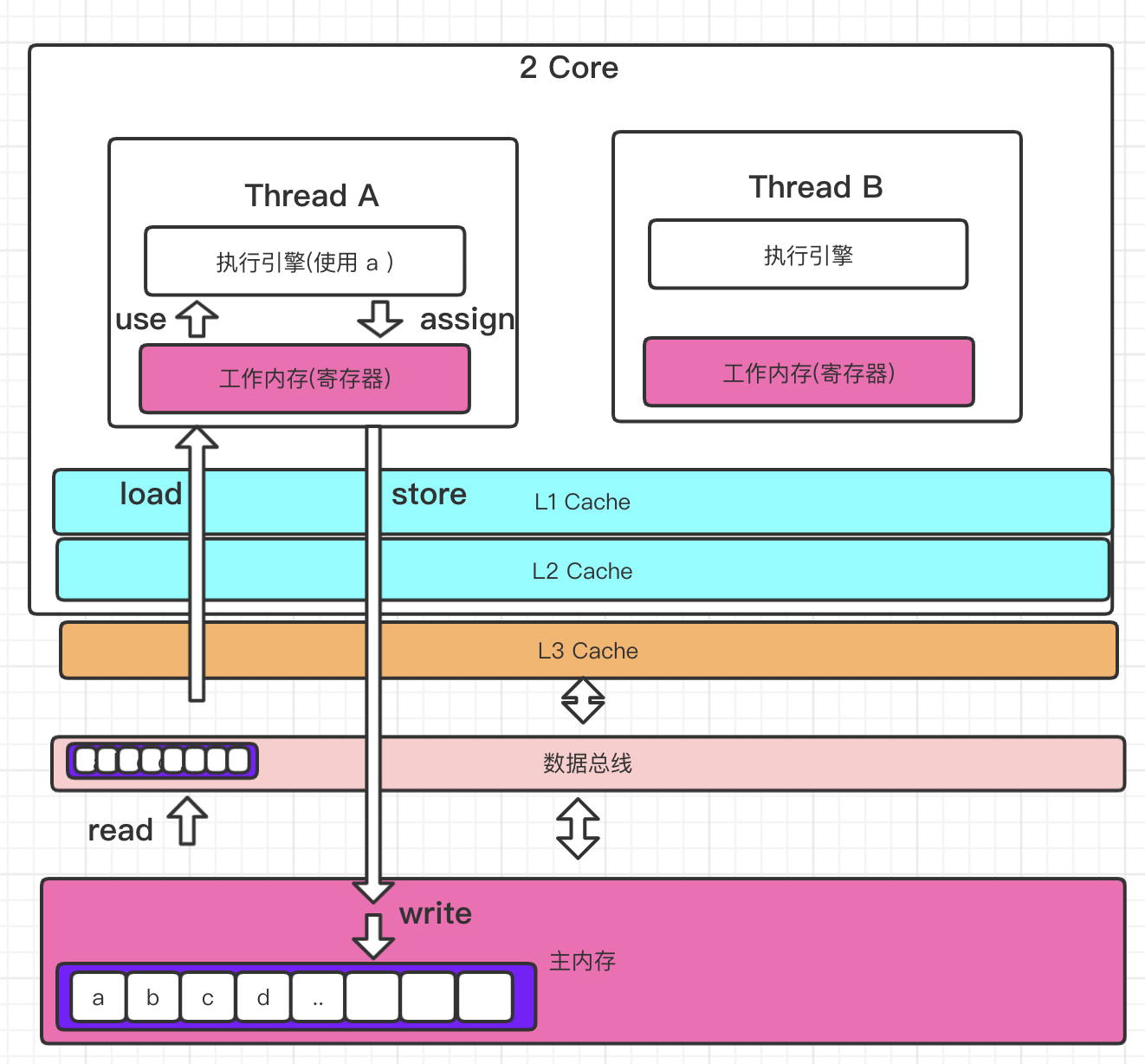
去掉三级缓存:
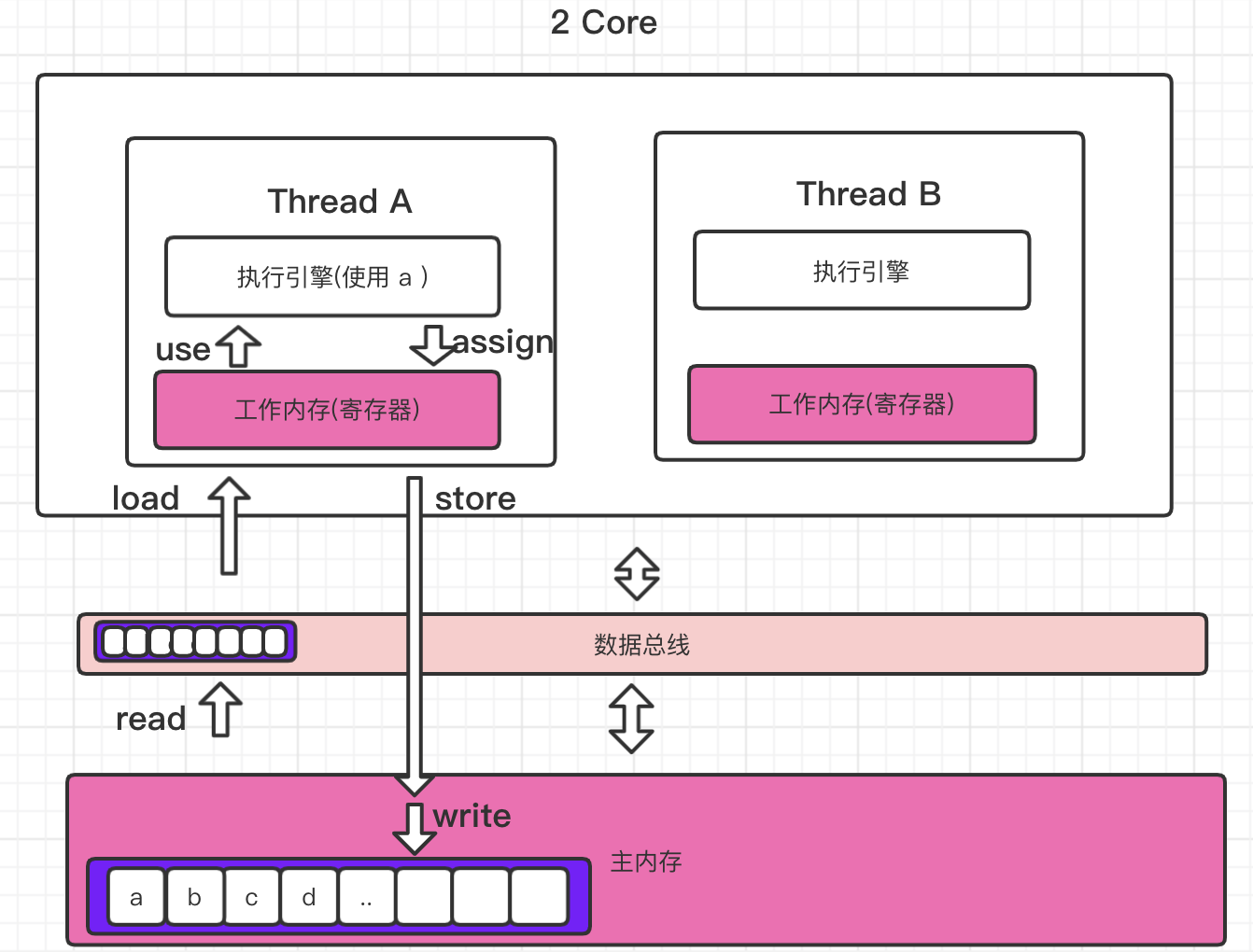
上面贴出来的是加载静态变量 a的过程, 可以结合前面的8种原子操作对照来看.
总线加锁
如果我们想保证一个数据在多线程环境下,多个线程访问同一个共享数据导致的安全问题,我们肯能会想到对共享数据加锁.如果对共享数据进行加锁,多线程访问功能数据就变成串行化访问了,这样根本不是我们的初衷,我们的目的是尽可能的提升CPU的使用率,性能太低.
MESI 缓存一致性协议
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱.这里就引出了一个一致性的协议MESI.
- Modidied 修改
- Exclusive 独占
- Shared 共享
- Invalid 无效
JMM将的颗粒度降低到写和存储的操作上, 读不需要锁,只是写和存储需要锁.
把锁加上之后的完整流程:
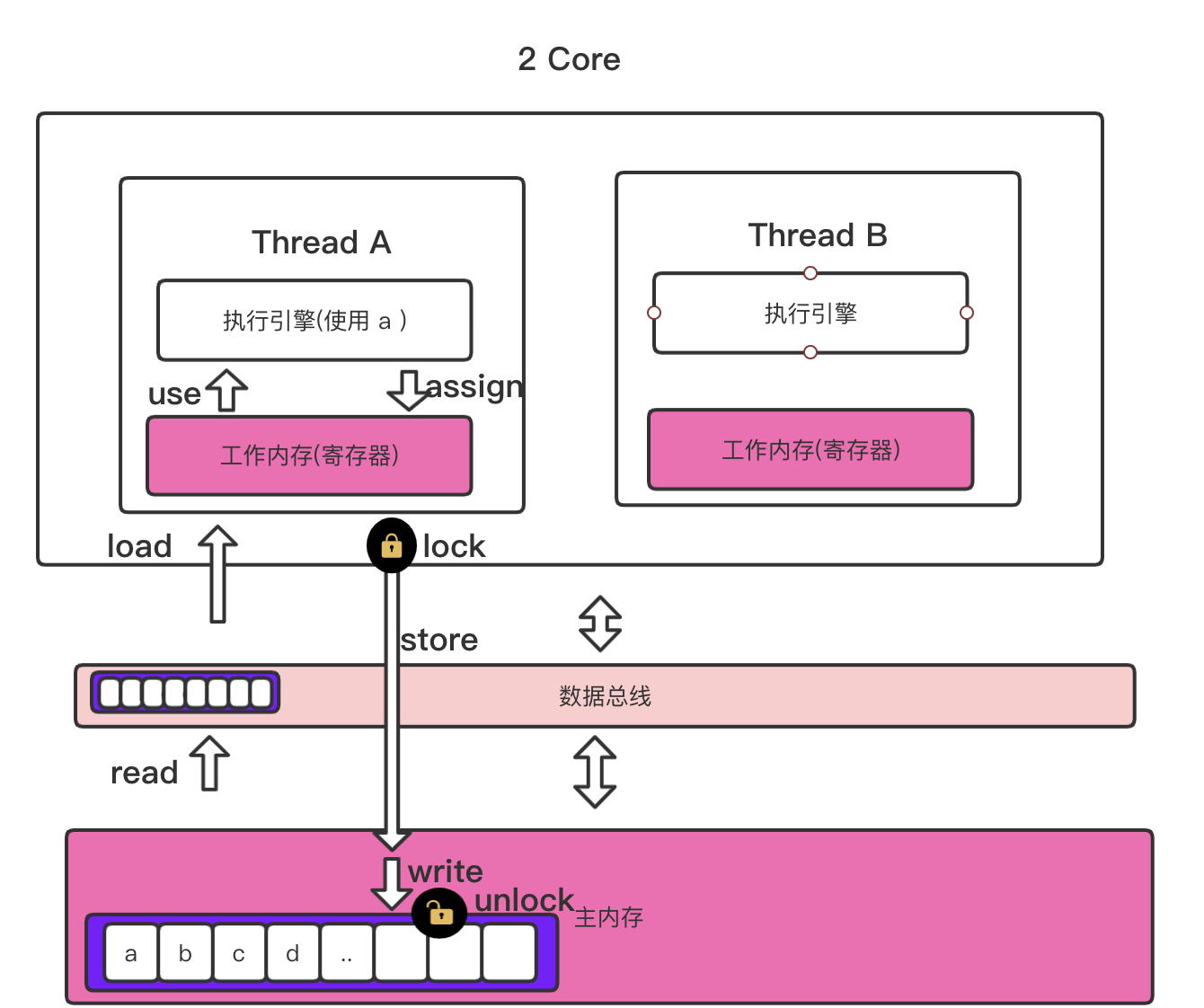
多个CPU从主内存读取同一个共享数据到各个线程的高速缓存,当其中一个线程修改了缓存里的数据,该数据会马上同步回主内存,其他线程通过cpu的总线嗅探机制可以感知到数据发生变化,从而将自己缓存里的数据失效,重新加载.
总线嗅探机制
在执行存储和写入操作时数据一定会经过总线,执行完存储数据已经到达主内存,也就是已经经过总线.
总线嗅探机制: 每个线程监听着总线,如果发现总线上执行了修改共享数据,就让该线程将自己缓存里的数据失效,重新加载.
JAVA虚拟机指定这一套完整的规范流程,在配合上volatile就能实现让Java程序在各种平台下都能达到一致的内存访问效果;
没有volatile下的JMM
没有volatile下的JMM,依旧没法保证共享元素的一致性.
我们知道volatile的作用是:
- 保证可见性
- 禁止指令重排
- volatile 保证不了原子性
下面来演示一个简单的例子:
1 |
|
运行的结果是:程序终止不了.
可是我们明明已经修改了flag的值,可是为什么还是终止不了呢?
我们的JVM只所以定制出JMM,就是为了尽可能的保证内存的可见性.
我们这里thread1用的flag是工作内存用的是主内存flag数据副本,并且while 循环执行的是一个空方法, thread1获得CPU得执行权,就疯狂的循环,几乎没有让出CPU的机会.
如果我们在while循环中加入点耗时的操作(比如创建对象,线程睡眠 或者使用System.out打印信息),这时CPU就有可能有时间去保证内存的可见性了.
如果我们将flag 静态变量加上volatile关键字,那就结果就不一样了, volatile 强制其被修饰的参数在线程间的可见性.
这里就不在贴出使用volatile修饰 和 在线程内执行耗时的操作 让程序顺利终止的代码了.
volatile 缓存可见性实现原理
底层实现主要是通过汇编lock前缀指令,它会锁定这块内存区域的缓存(锁定缓存行),并回写到主内存.
1:会将当前处理器缓存行的数据理解回写到系统内存.
2:这个回写内存的操作会引起其他CPU里缓存了该内存地址的数据无效(EMSI协议).
1 | -server -Xcomp -XX:+UnlockDiagnosticVMoptions -XX:+PrintAssembly -XX:CompileCommand=compileonly,*VolatileVisibilityTest.prepareData |