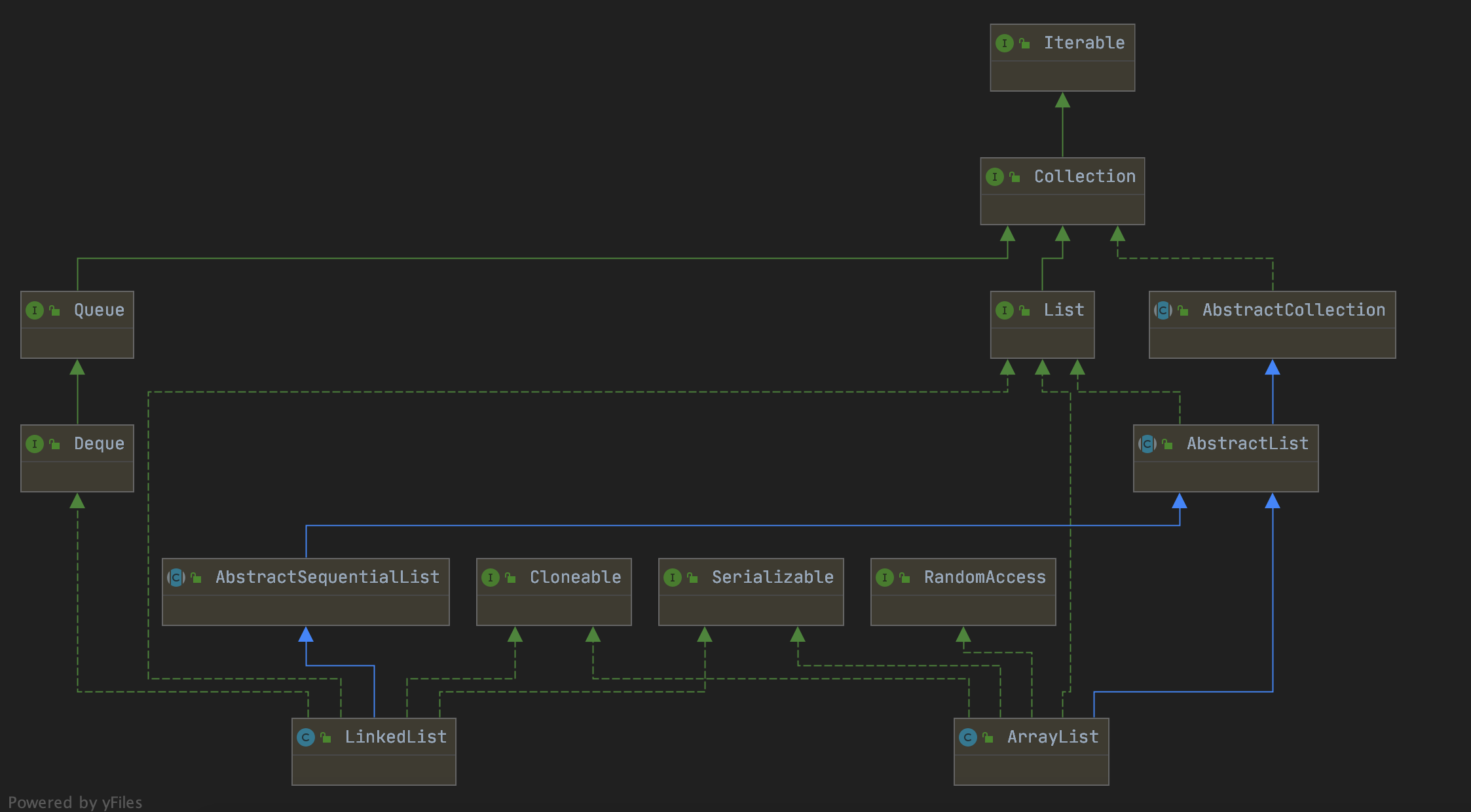
/** * src 原数组 * srcPos 原数组偏移位置 * dest 目标数组 * destPos 目标数组偏移量 * length 要copy的数据个数 * / public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
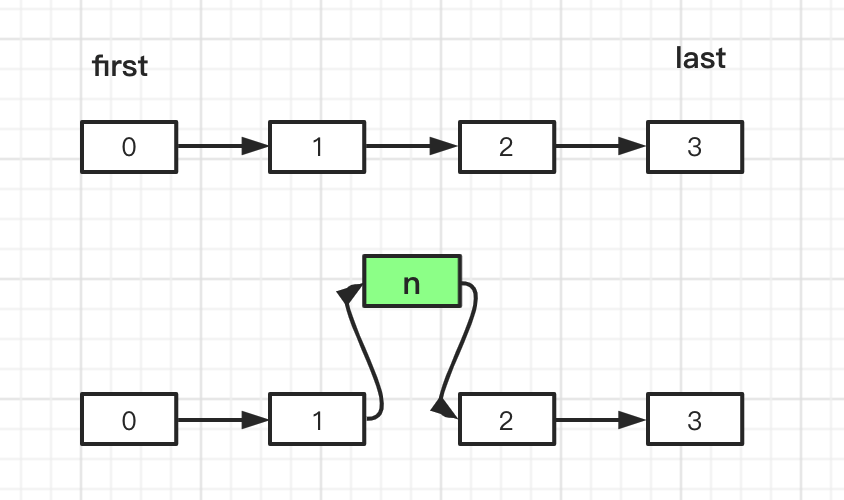
这里结合add(int index, E element) 来理解就是,将elementData数组,中index位置之后的length = size - index 个元素拷贝一份,都贴到目标数组dest (还是elementData)的destPos(index + 1)位置,也就是index后面的位置,如果感觉费劲,就直接看图理解吧。
remove()方法
先看代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
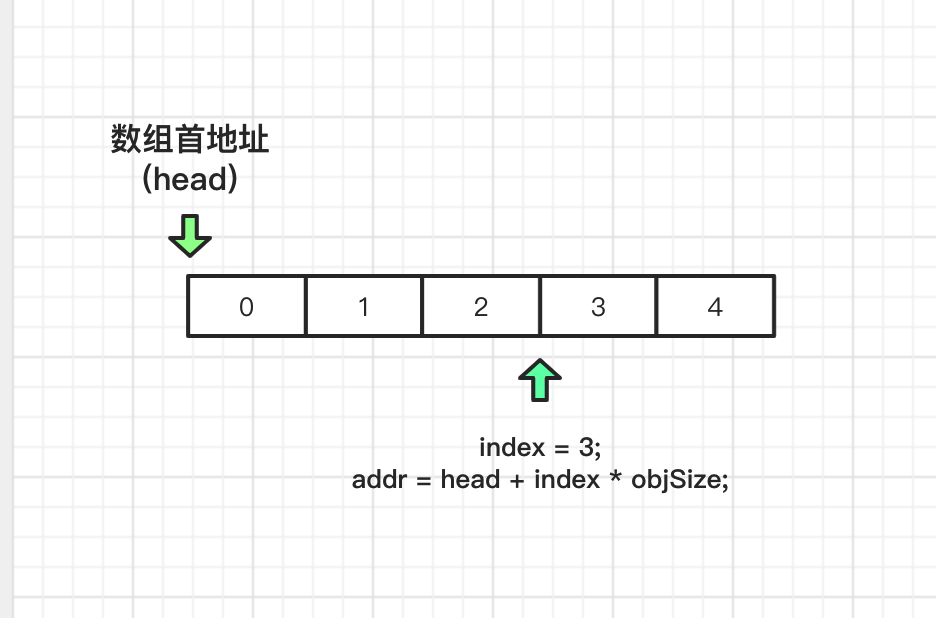
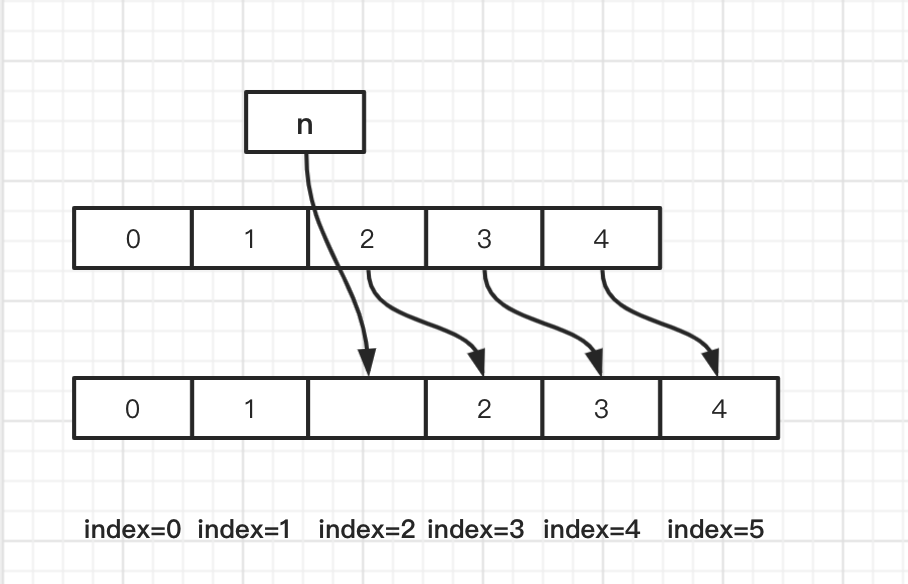
public E remove(int index){ //检查 index rangeCheck(index); //操作次数计算加1 modCount++; E oldValue = elementData(index);
int numMoved = size - index - 1; // 如果不是最后一个元素: 将index 位置之后元素都向前移动一位 if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); // 将数组尾部的元素 赋值为null elementData[--size] = null; // clear to let GC do its work
return oldValue; }
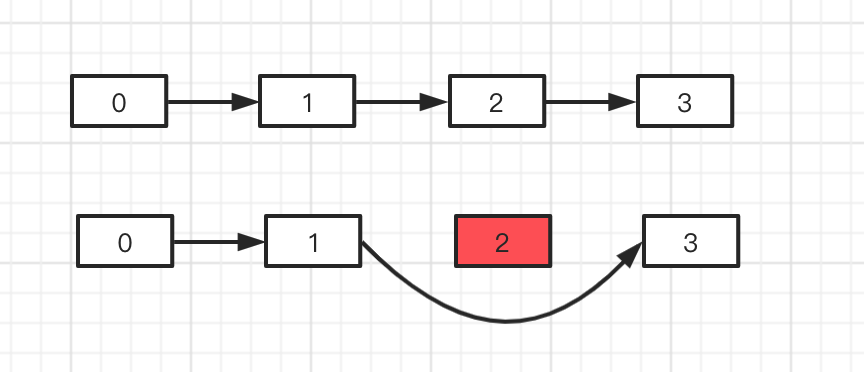
删除操作,就是将index位置之后的所以元素都向前移动一位,index + 1 位置的元素覆盖了原 index 位置的元素, 最后将数组尾部多出来的元素赋值为null;
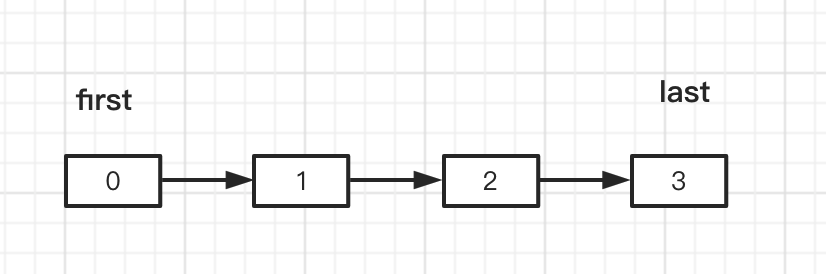
voidlinkLast(E e){ final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else // 如果不是第一个元素(空链的时候),将next指向最后一个元素 l.next = newNode; size++; modCount++; }
public E remove(int index){ // 检查 index checkElementIndex(index); return unlink(node(index)); }
//根据index 查找 节点元素node Node<E> node(int index){ // 如果 index 在前半段(index / 2) if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { // 如果 index 在后半段 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } // 将 node 节点 移除链表 E unlink(Node<E> x){ // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev;
if (prev == null) { first = next; } else { prev.next = next; x.prev = null; }
if (next == null) { last = prev; } else { next.prev = prev; x.next = null; }